Hello! I am Andrew Tatarinov. We are engaged in projects in the field of machine learning and data analysis. In this article, I will talk about advanced personalization based on the ML model. We will also cover the development of a recommender system that can be built into all website listings, taking into account the user's interests as much as possible. Finally, I will show how these recommendations influence conversion rates.
Personalization is the fuel for e-commerce projects. Without it, the engine of your business will not start. If the user can't find the product they want in the online store, they leave, and you lose money. Every year, personalization is becoming more important as customers' demands grow and they expect businesses to understand their needs much better.
Personalized recommendations allow users not only to quickly find the right products but also to buy more. It was proven by our experience tripsider.com, a marketplace for small group tours.
There are almost 40,000 offers. Usually, the user does not look over all the offers for their query, and they choose from what they find on the first two pages of the search or in the «Recommended» blocks on the home page.
This is quite usual for this type of site. That's why personalization is so important for marketplaces and online stores with a large range of products. But personalization comes in many forms.
What’s wrong with personalization in e-commerce
In most cases, personalization in e-commerce works only in blocks like «You might also like,» «Others also bought,» or through upsell recommendations in the cart. It's not because these are the most effective options. It's just that integration there is the cheapest and easiest.
In fact, personalization should target any listing on the marketplace. However, it is difficult to get into every listing, because they all have different non-trivial logic by which the listing is formed. That is why most players prefer a simpler and cheaper option, which is to implement a widget «You might also like,» which is quite limited not only in functionality but also in efficiency.
Just compare: a widget of four objects or 100 personalized products from the listing. Of course, there is more profit in re-sorting the main listing than in introducing a small block with a limited offer.
Although personalization in listings is difficult, there are e-commerce systems on the market that implement personalization in the main feed. For example, AliExpress. If you click there on a radio-controlled car, you'll have the entire feed filled with these cars the next time you upgrade. The same goes to TikTok..
We were inspired by these examples and came up with a personalization strategy that allows for integration at the re-sorting level of any listing with its own formation logic. We don't just give a list of recommended objects by API, we:
- collecting lazy views and a lot of behavioral information,
- resorting product lists for each individual customer.
This is the strategy we used.
Going into details
Let's talk a bit more about our re-sorting method and personalization strategy in general.
Imagine the scenario. The user is looking for something on the site, they set the filter «Italy» in the search, and find there 15,000 tours. We get all these tours on the input — they are already filtered by some logic, valid for our system. Next, we decide which 20 rounds to show on the first page to increase the probability of user conversion to click or purchase.
We call it a re-sorting API. It was the re-sorting that laid the foundation for implementing our API.
Collecting and processing data
For personalization to work, you need to collect the user data. Together with our client we created a system to collect information showing what the user saw on the page, what they clicked on, and where they went. The client's team was doing the rework of the frontend, and we were doing the receiving part and some regular data processing.
The key to our data collection is accounting of lazy views. There is no collection of information about views without interaction in typical tracking. However, we need to know that the user saw these 20 products, but did not choose anything and did not do anything. This information is needed for statistics and for training the ML model.
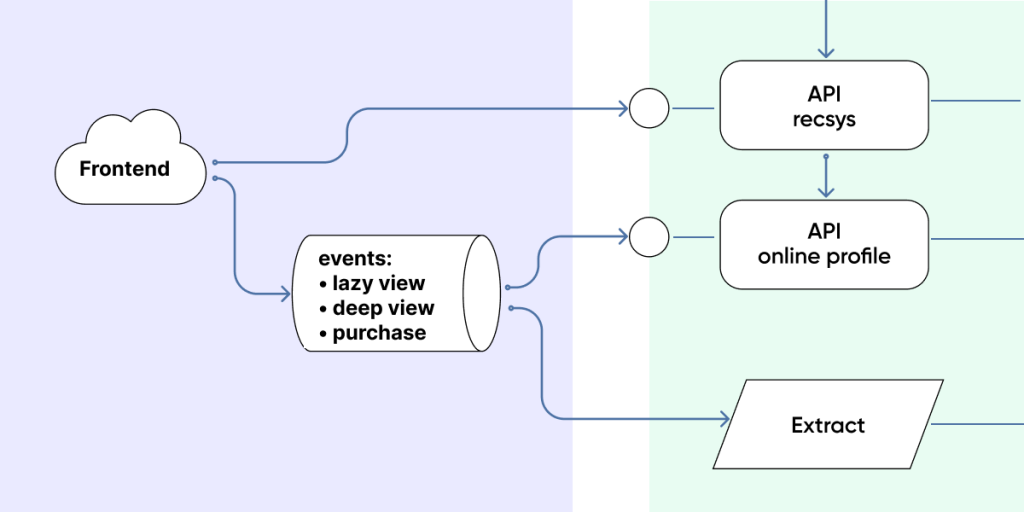
So, we fine-tuned the data collection system (both from the customer's side and ours) so that we could get the information about:
- lazy views,
- deep views (product card views),
- shopping.
As the result it looks like this:
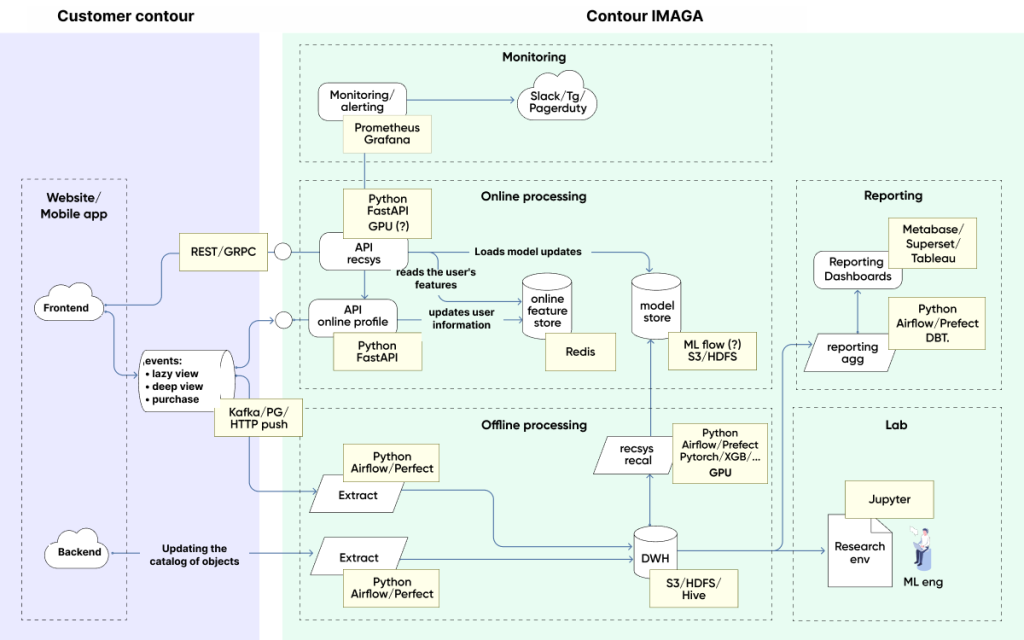
Data pours in from the frontend, we receive it, and put it into two places:
1. 1. Long-term storage for retraining the model of counting statistics.
2. An online profile that instantly tells us about the user's preferences and the behavior they have just exhibited.
Our ideal scenario goes as follows. The user clicks on a product page, does something with a tour, and on the next page, they see the output, which is personalized and based on their interaction with that tour.
To do this, we have a second branch of the user's online profile, which receives a real-time stream of events from the frontend and holds a stripped-down but real-time picture of the user.
Our ML-based recommendation API, which implements the most important method, the product list re-sorting method, is next in line. It uses information from the online profile to find out the characteristics of the user that we are re-sorting for, and keeps in memory a personalization model — there can be several of them, as models can be substituted.
This online work cycle takes half a second while the user is interacting with the site.
There is another long cycle of interaction — every hour, we take the accumulated statistics, recalculate the recommendation matrices, and forcibly update the model in the API. About once an hour, we update the pre-calculated recommendations for each user.
Recommendations strategies
There are three situations when we make user recommendations:
1. This is the easiest one: we have a user who has been on the site for more than 30 minutes. That means they are already caught up in the hourly cycle of retraining. In this case, we just use a well-calculated vector of user characteristics and make good recommendations. They turn out to be of the highest quality.
2. The user has not been here for long, they are not yet in the calculated features, but they have already exhibited their behavior somehow. For example, they clicked on a product. In this case, we make a good guess about their preferences based on the qualities of the product they have shown interest in and form recommendations for them.
3. The hardest case is the cold user. They have just shown up, we don't know anything about them, but we still need to recommend something to them. In this case, we usually use static features, which are expressed not in behavior but in parameters (what language is chosen on the site, from which region, from which device, etc.). We use this to make a guess as to what should be recommended to them.
All three strategies work simultaneously.
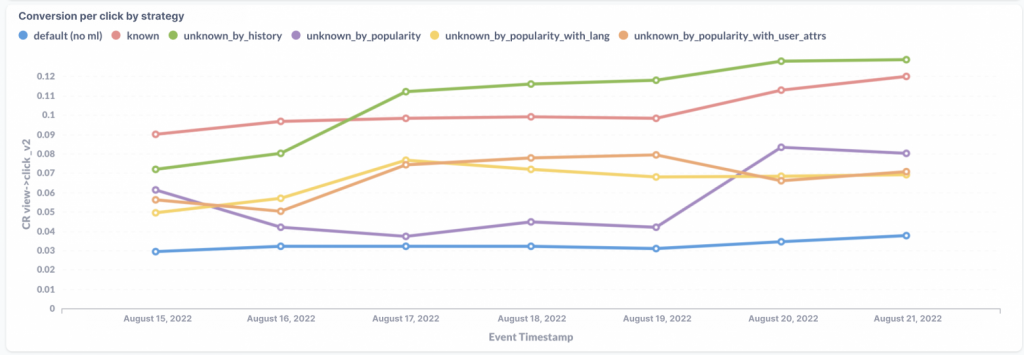
Unfortunately, most of the views are accounted for by cold users. That's why we are actively working on improving cold recommendations. We try to include there as much static information as possible. For example, try to take into account the advertising campaign, which brought the user here, learn to understand the advertisement text, and take it in the recommendations. Apart from that, the following points are considered:
- user's landing,
- the model of the phone which they used to log in,
- the language of the user’s site/browser,
- user's location.
Of course, the list of these types of data is limited, but this is exactly what we can learn about the cold user.
Results
We want to have every list of items on the site sorted by our re-sorting strategy. After all, its clickability is definitely higher than the default one.
The site now has the strategy integrated into some of the listings. Right now, our status can be described as follows: we entered the battle, went through the initial launch phase, and are in the phase of gradual improvement. It's been two months from scratch to launch, and we're ready to share the first results.
The average conversion from show to click without recommendations is from 3% to 4.5%. Clickability of personalized offers at the start of the project is from 6% to 9%. Doubling the target action is quite impressive. And we haven't finished the project yet.
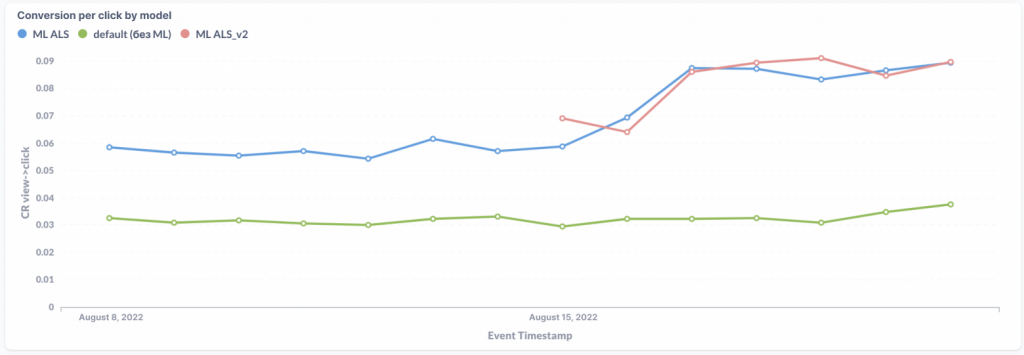
Our cold recommendations work so far the same way as sorting by customer popularity. We are actively improving the recommendations to make them more effective. The basic problem with such recommendations is that we know very little about the user, but we experiment with the available data and try to get the most out of it.